
Beyond MTTR: A Measurable Framework for True Cyber Resilience
Rubrik Zero Labs proposes the adoption of a holistic Cyber Resilience Lifecycle strategy for continuous program improvement, powered by a tactical five-stage MTTR Pipeline for granular incident measurement and improvement.
blog Beyond MTTR: A Measurable Framework for True Cyber Resilience
Rubrik Zero Labs proposes the adoption of a holistic Cyber Resilience Lifecycle strategy for continuous program improvement, powered by a tactical five-stage MTTR Pipeline for granular incident measurement and improvement.
blogFor decades, IT organizations have anchored their disaster recovery strategies to three metrics: Recovery Time Objective (RTO), Recovery Point Objective (RPO), and Mean Time to Recovery (MTTR). While essential, these metrics have become dangerously coarse and insufficient for the modern cyber threat landscape. A single, blended "MTTR" number is a lagging indicator that provides no actionable insight. It tells you what happened, but not why it took so long, where the bottlenecks were, or how to fix them.
True business resilience requires a new, phase-aware framework that breaks incident recovery events into distinct, measurable stages. Rubrik Zero Labs proposes the adoption of a holistic Cyber Resilience Lifecycle strategy for continuous program improvement, powered by a tactical five-stage MTTR Pipeline for granular incident measurement and improvement.
By combining this framework with real-world performance benchmarks, we can finally move from vague metrics to the actionable data needed to link resilience to business outcomes and build a confident, measurable, and mature recovery posture.
The "Coarse Metric" Fallacy
Relying on a single MTTR number is like judging a factory's efficiency by its "average time to ship," ignoring the separate, critical stages of order processing, manufacturing, quality assurance, and logistics. We have been flying blind, unable to answer the most critical questions, including:
Was the delay caused by slow detection?
Did we struggle to identify the blast radius?
Did it take hours to find a clean, uncompromised backup?
Was the application team simply not ready to validate the restore?
Real-world disasters perfectly illustrate this problem. A 2024 incident impacting healthcare operations in the United States provided a devastating example. The public-facing metric was a "month-long outage," but this coarse number provides no actionable insight. The reality was a catastrophic breakdown across multiple, unmeasured phases. The company took systems offline "as a precaution," indicating a critical failure in their ability to quickly understand the scope of the breach. Even after data was technically restored, providers hesitated to reconnect due to a lack of trust, highlighting a massive failure in validating the recovery and restoring business confidence.
This problem is not unique to healthcare. Consider the 2019 ransomware attack on a major global manufacturing firm. The public metrics were "a $70M+ financial loss" and a "month-long disruption." Again, these are coarse metrics. The reality was a multi-stage failure: a forced shutdown of the entire global network (a failure in Scoping) and tens of thousands of employees forced to use pen and paper for weeks (a failure in Validation).
These "dark matter" metrics—the time spent in non-restore phases—are where true resilience is won or lost.
A New Model: The Cyber Resilience Lifecycle
To build a mature program, organizations must adopt a continuous, programmatic lifecycle that goes beyond a single incident. This lifecycle involves four key stages:
1. Resilience Assessment: Define and understand the current security posture and risk profile. This is the foundational "Identify" stage, mapping critical business services to their underlying technical dependencies.
2. Establish MVB (Minimum Viable Business): Identify the key assets, applications, and infrastructure required to keep the business operational. This defines the "what" and "in what order" for any recovery.
3. Crisis Simulation: Move from theory to practice. Actively stress-test defenses and security posture in sandboxed environments to measure outcomes against the MVB.
4. Resilience Optimization: After an incident or simulation, analyze the performance of every stage to identify and fix bottlenecks for improved future outcomes.
This lifecycle transforms resilience from a static, "set it and forget it" project into a living, continuously improving business function.
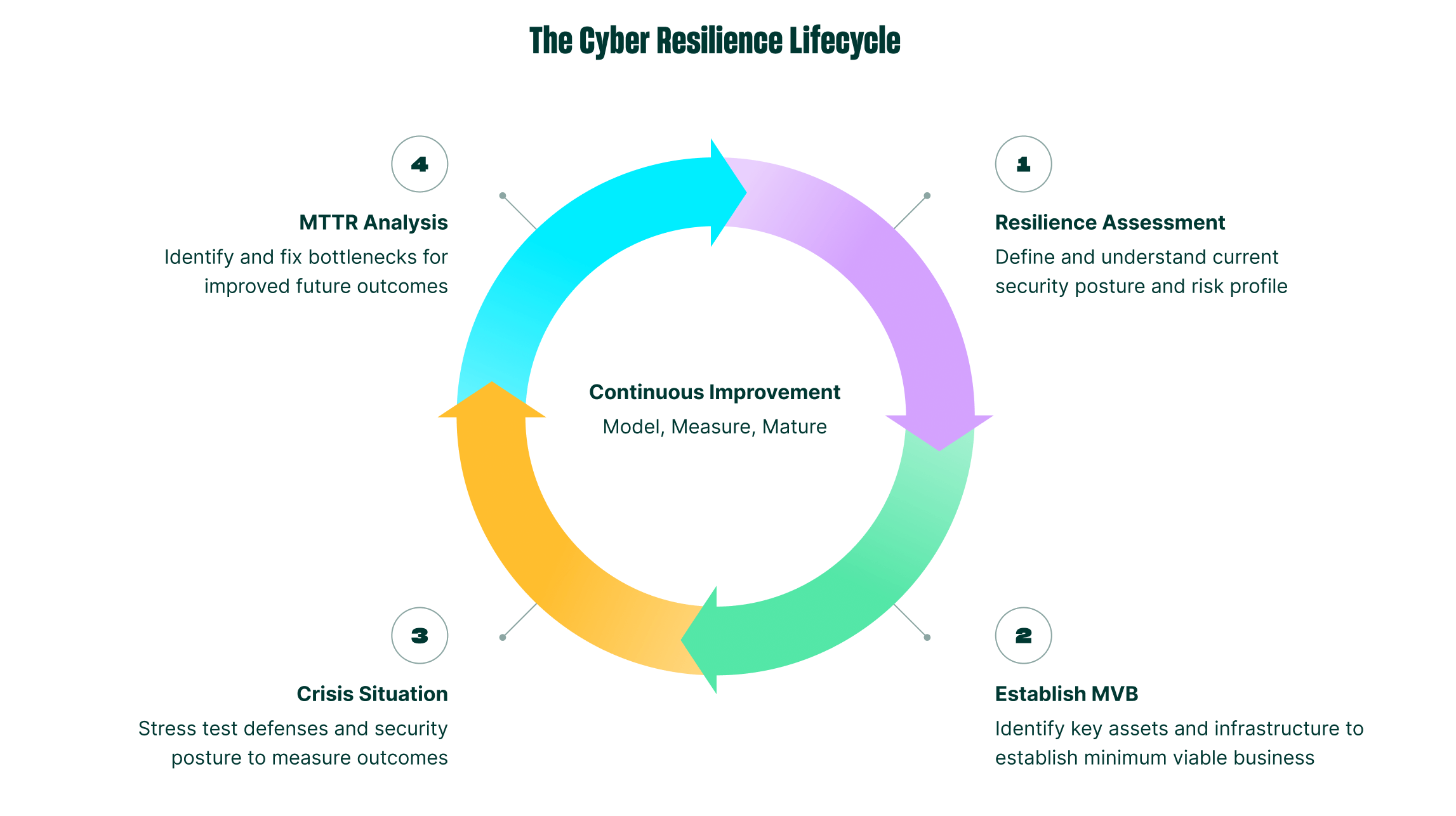
Figure 1: The Cyber Resilience Lifecycle
"Resilience Optimization" should be powered by a tactical framework that dissects a single recovery event into five measurable phases. This pipeline is the key to unlocking actionable data.
1. Mean-Time-to-Detect (MTTD): The "time to awareness," from the initial adversary impact or alert to the confirmation that a recovery is required
2. Mean-Time-to-Scope (MTTS): The "time to a plan," from detection validation to a locked, confirmed list of all recovery objects
3. Mean-Time-to-Select-Good-Snapshot (MTTGS): The "time to confidence," from a locked scope to identifying a clean, uncompromised snapshot to restore from
4. Mean-Time-to-Restore (MTTr): The traditional "MTTR," the time from triggering the restore to the data being made available to the workload (e.g., via Live Mount or Export)
5. Mean-Time-to-Validate (MTTV): The "time to business function," from initial data to full application health verification and sign-off
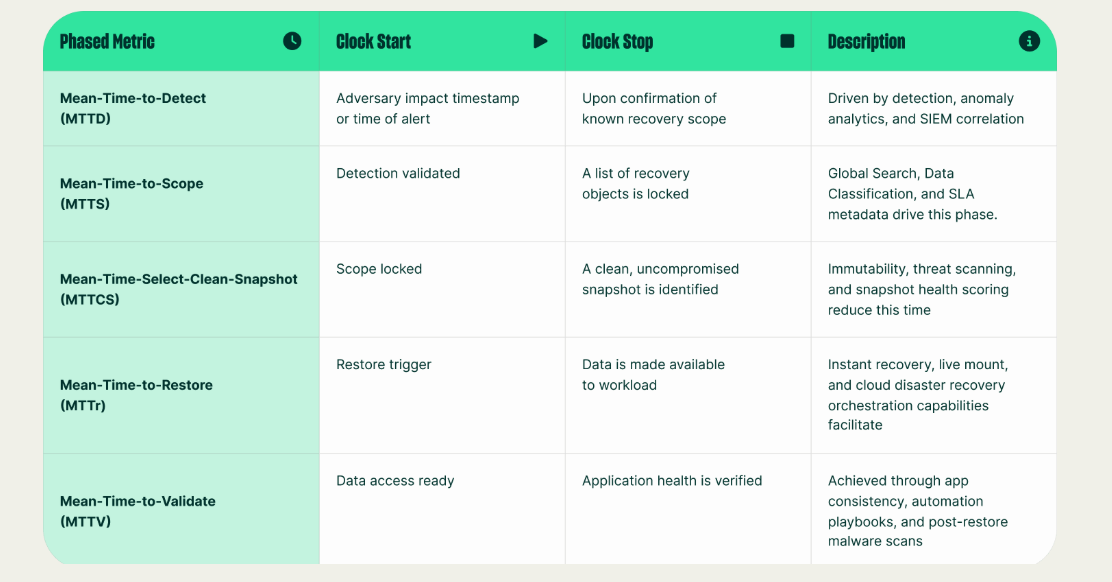
Figure 2: The Five-Stage Tactical MTTR Pipeline
Let's re-examine the global manufacturing firm's incident through this 5-stage lens. A traditional coarse metric just shows a failure of "weeks." But the pipeline would have provided an actionable improvement path:
MTTD: How long did it take from the first encrypted file to a formal incident declaration? Was this 10 minutes or 4 hours? This is an actionable number.
MTTS: The team spent hours manually deciding to shut down the global network. This massive, unmeasured MTTS highlights a critical need for better data classification and blast radius discovery tools.
MTTGS: How long did it take to find and verify a "golden snapshot" for each of the company's dozens of plants? Was this 1 hour or 2 days? This pinpoints the need for immutable, threat-scanned backups.
MTTr: The technical restore itself took weeks. This metric isolates the data transfer speed and restores infrastructure as a separate bottleneck to be solved.
MTTV: The business ran on pen and paper for over a month. This metric proves that the recovery failed at the validation stage. It highlights the need for automated validation playbooks and application-owner sign-off.
This is the actionable insight. The problem wasn't just the "restore"; it was the catastrophic, unmeasured time lost to scoping and validation. This is the data that transforms a post-mortem from a blame game into a concrete improvement plan.
Using MTTr to Prove the Thesis
Today, a significant telemetry gap exists. Most organizations have no automated way to measure MTTD, MTTS, MTTGS, or MTTV. This data is often buried in disparate SIEM logs, incident tickets, and spreadsheets.
To understand the value of a phase-aware framework, we can look at the one stage where we do have rich, high-fidelity telemetry: Stage 4, Mean-Time-to-Restore (MTTr). Our analysis of this single stage proves our central thesis in miniature: even here, a blended average is meaningless. Performance is dictated by the object type and restore method.
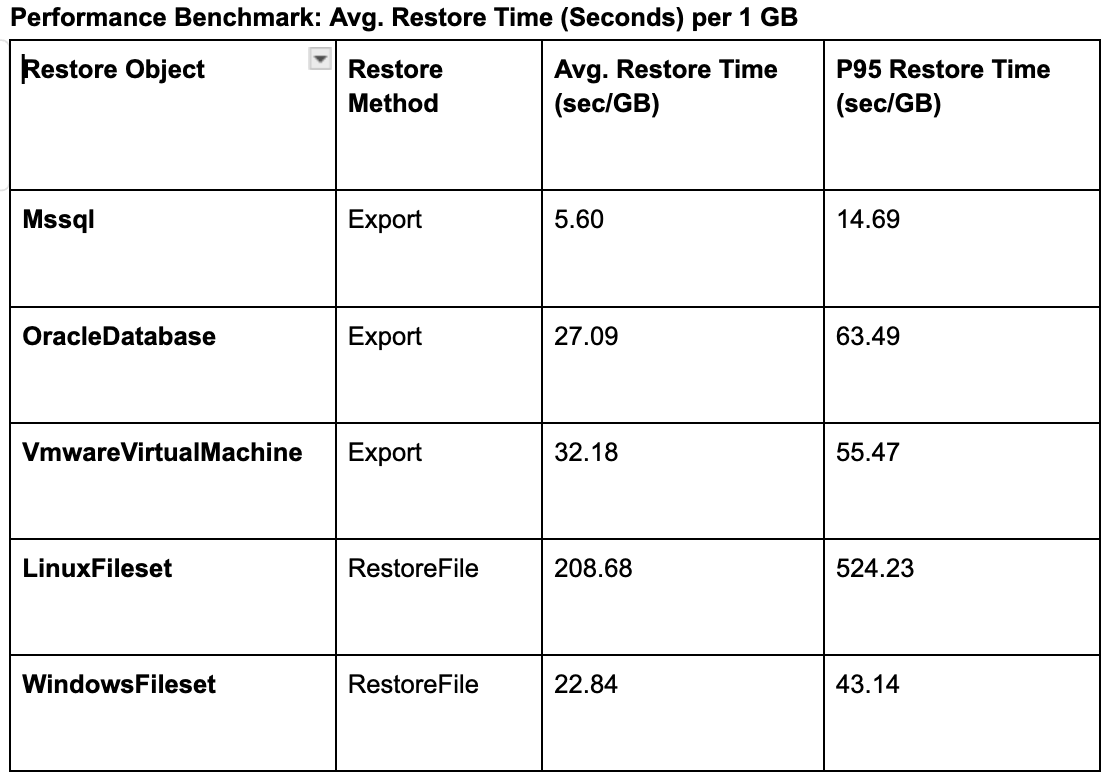
This data provides a powerful benchmark for the technical MTTr phase. But more importantly, it serves as a critical analogy for the entire pipeline.
If a single, blended "restore time" is meaningless because it incorrectly hides the vast difference between an Mssql and a LinuxFileset restore, then a single, blended "Total Recovery Time" is even more meaningless because it hides the vast difference between a 15-minute MTTD and a 2-day MTTV.
This table proves that granular, phase-aware measurement is essential. The goal is not just to optimize this one small stage, but to apply this same level of analytical rigor to the "dark matter" phases of detection, scoping, and validation, where the real bottlenecks lie.
The Path Forward: Operationalizing the Full Pipeline
This framework is not just an analytical model; it's a plan for action. To achieve true resilience, we must operationalize the measurement of all five stages.
Step 1: The MTTR Dashboard
We must first provide actionable visibility. An MTTR Dashboard is the first step. This dashboard must feature:
Phase-Aware Visuals: A waterfall chart visualizing time spent in each of the 5 stages for every incident.
Actionable Metrics: Clear tracking of P50/P90 performance and SLA breach rates.
Cohort Benchmarking: The ability for customers to anonymously benchmark their performance against their industry, region, or company size.
Step 2: The "Resilience Module" (ITSM Integration)
To close the telemetry gap, we must integrate this framework directly into the ITSM platforms that run the business. We propose the creation of a new "Resilience Module" in tools like ServiceNow and Atlassian Jira. This module would not replace existing tools but would serve as the central orchestration and measurement layer to:
Integrate with the CMDB: Dynamically link assets to their Business Impact (Stage 1) data.
Integrate with Incident Management & SIEMs: Automatically trigger a "resiliency timer" the moment an incident is declared, capturing MTTD and MTTS.
Integrate with Recovery Platforms: Pull in real-time API telemetry for MTTGS and MTTr.
Orchestrate Validation: Automatically assign validation tasks to application owners and track their response time, capturing MTTV.
Step 3: The Crisis Simulation Engine
Finally, we must evolve from passive measurement to active crisis simulation. This will allow organizations to run realistic, software-driven scenarios in sandboxed environments that actively measure performance against MVB and truly maturing resilience posture.
By adopting this five-stage pipeline, building the tools to measure it, and integrating it into core business operations, we can finally move from a reactive posture to a predictive one—and drive recovery with data-driven confidence.